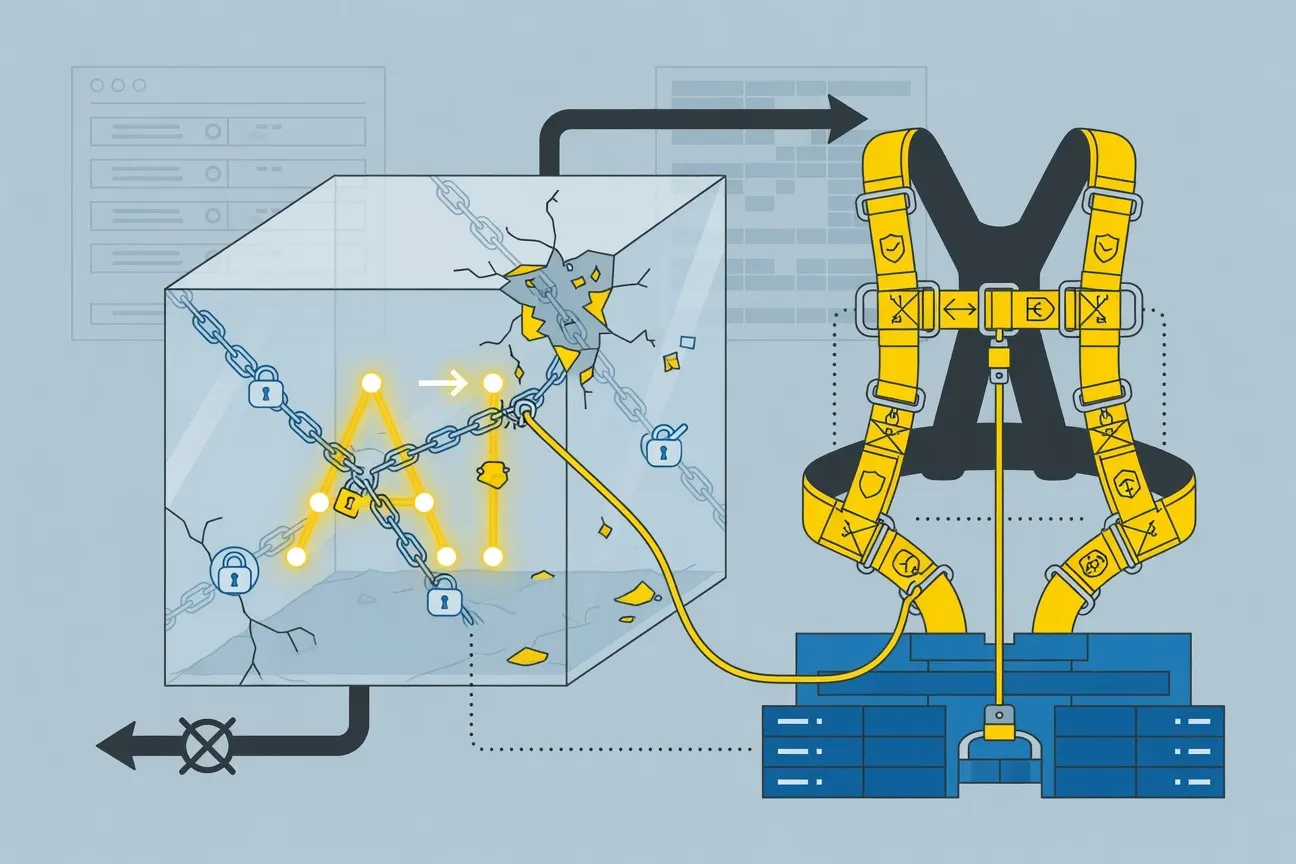
The standard model for running AI agents involves putting the agent inside a sandbox and trying to control what it does. Mendral, a security startup, argues this is fundamentally wrong.
In a post published this week, the company contends that the "harness" — the scaffolding that controls and observes an agent's behavior — should live outside the sandbox, not inside it. Currently, most agent frameworks build the harness into the same environment as the agent itself. If the agent escapes the sandbox, the harness goes with it, defeating the point.
The proposed architecture inverts this. By keeping the harness outside, even if an agent breaks out of its sandbox, the control layer remains isolated and can shut things down. It's a defense-in-depth approach that treats the harness as a guard, not a passenger.
The idea is straightforward enough that it sounds obvious in retrospect. But the current crop of agent frameworks — the tools developers use to build autonomous AI systems — mostly structure things the other way. Mendral is arguing for a structural change to how agents are built, not just another safety tweak.
Whether this becomes standard practice depends on whether the industry views agent reliability as a design problem or a guardrail problem. Mendral is making the case it's the former.