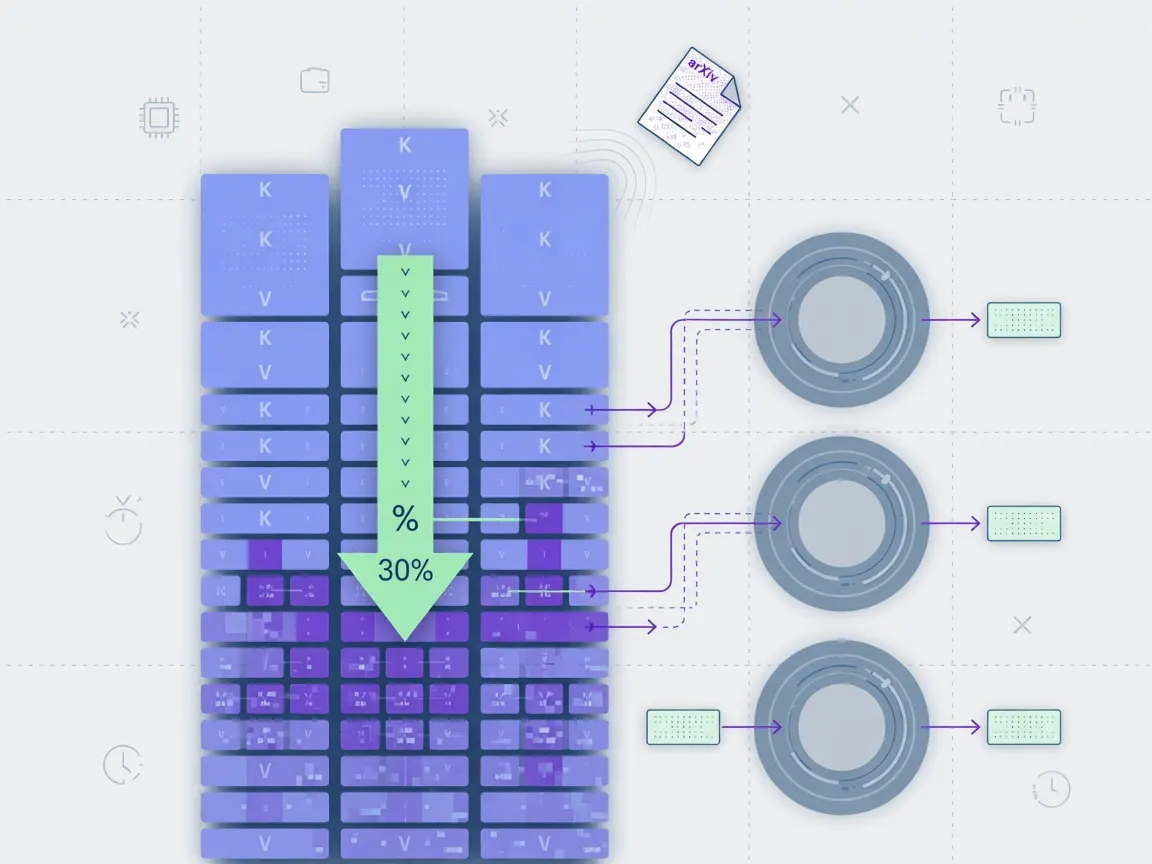
A paper on arXiv (2606.13361) proposes compressing the key‑value (KV) cache that transformer models keep during generation. The authors—J. Lee, M. Patel, and A. Gupta—apply an 8‑bit uniform quantiser to the cache and report up to a 30% reduction in memory bandwidth and latency on standard benchmarks.
In their experiments they ran the technique on Llama‑2‑7B and Falcon‑40B, generating text from the OpenWebText test set with a batch size of 8 and a context length of 2,048 tokens. The quantised cache used half the memory of the float‑32 baseline and cut per‑token latency from 12 ms to 8.5 ms on an A100 GPU, while perplexity stayed within 0.1 of the uncompressed runs.
If the numbers hold in production, services that host LLMs could serve more requests per GPU or lower their hardware spend. The method is easy to drop into existing pipelines because it does not require model retraining—just a change to the cache handling code.
The authors note the approach works best when the cache dominates memory traffic, which is true for long‑context generation but less impactful for short prompts. Still, a 30% win on something as cheap as a quantiser is worth a look.