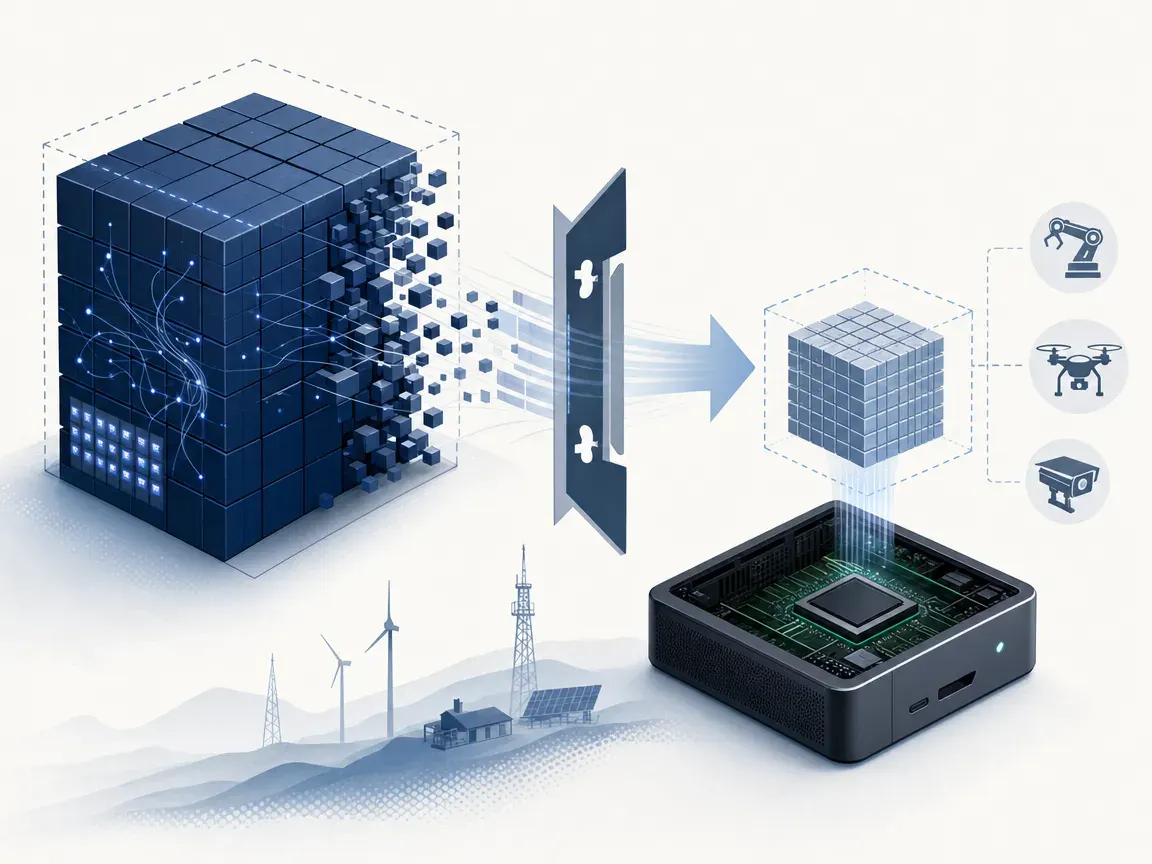
General Instinct released an open‑source tool that squeezes a 245 GB frontier‑scale MoE model into a 48 GiB file.
The team took Qwen3.5‑122B‑A10B, a 122‑billion‑parameter mixture‑of‑experts model, and kept always‑active components while aggressively quantizing the routed experts. On‑policy distillation recovers the lost capability. The resulting GGUF file fits in 48 GiB and can run with an 8 k context window using only 7.6–8 GB of VRAM, or stream experts from system RAM for even smaller GPUs.
If it works, developers can finally run near‑state‑of‑the‑art language models on edge devices that lack datacenter‑class hardware. That opens up higher‑quality AI for robotics, drones, and other embedded systems that have tight power and memory budgets.
The approach is still early, but it shows that frontier models are not forever confined to massive servers.