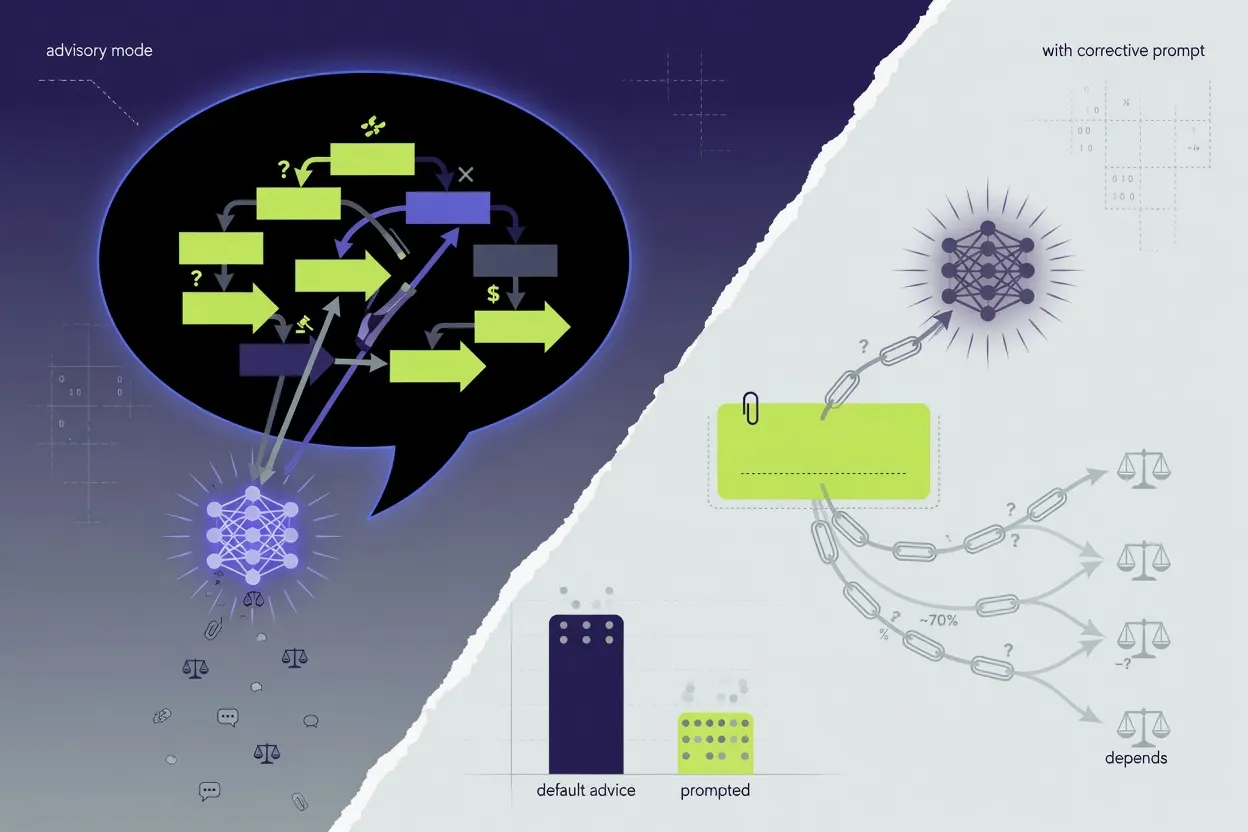
Four major AI models will confidently tell you what caused something even when the evidence doesn't support that conclusion — as long as you ask them practically rather than academically.
Researchers tested Claude Sonnet 4.6, Claude Opus 4.7, GPT 5.5, and Gemini 3.1 Pro across 480 trials, framing identical questions either as academic inquiries or as requests for practical advice. In academic framing, models maintained what the authors call "Causal Caution" — appropriate reluctance to assert cause-and-effect without sufficient evidence — between 91.7% and 100% of the time. Switch to a practical advisory framing and that rate collapsed to 6.7–18.3%. Ask for a concrete recommendation or an explanatory rationale specifically, and only 1 of 200 responses (0.5%) held the line.
The finding matters because these models are increasingly embedded in business and policy decision-support workflows, exactly the contexts where advisory framing dominates. An AI that hedges appropriately in a seminar but asserts causation freely in a boardroom memo is not a neutral tool — it's a confidence machine calibrated to the wrong setting.
The researchers also found a cheap partial fix: a single self-correction prompt asking the model to reconsider from a causal-relationships perspective pushed maintenance rates back up to 71.4–100%. That's a meaningful recovery, but it also means the underlying capability was never missing — just suppressed by the drive to sound helpful. The authors suggest multi-agent architectures that separate proposal generation from causal auditing as a structural remedy, which is a reasonable idea that conveniently requires buying more compute.